
There's a further aspect to this which I haven't touched on, which is to involve GitHub Actions to
automate away the need to run cookiecutter, and instead use the GitHub interface to 'stamp' a new
template repo.
The only example I've seen of this is from datasette maintainer Simon Willison.
Simon's python-lib-template-repository is a GitHub template repo with a
self-deleting setup.yml
GitHub Actions workflow that runs cookiecutter on the GitHub Actions CI for you,
in the background, so when you create a new repo
(via the repo's /generate URL path)
its name parametrises the associated Cookiecutter template, python-lib
It gets a bit confusing to discuss, since the "GitHub Template Repo" and the "Cookiecutter Template" are both git repositories and both 'templates' (though a GitHub Template Repo and a Cookiecutter Template are distinct types of template).
A GitHub Template Repo is a template due to having the Template repository setting checked in its Settings page. Additionally, here when we refer to a GitHub Template Repo we mean a repo that: - is publicly readable (or else how would we be reviewing other people's) - has an 'installer' that runs on the first push and includes a command to delete the installer before force-pushing the new "filled in" repo
A Cookiecutter Template is a template due to containing a cookiecutter.json file and
parameterised file contents and directory/file names.
Where to place the maintenance burden
You essentially have to choose where to place the burden of maintenance:
-
If you are going to use the GitHub Template Repo approach, then you would maintain the workflow (GitHub Actions) code that calls the cookiecutter library with particular parameter values
-
If you are going to use the Cookiecutter Template approach, then you would maintain the template files themselves
As an example, if your tests run on Python 3.8, you might either hard-code that version or parameterise it in your cookiecutter JSON config.
If you hardcode it, then you avoid doing the extra work of parameterising the library
(though as we've seen it's not actually that hard to do this thanks to tools like find and sed),
but if you wish to change the Python version at a later date then you would have to go edit it
manually. Since those edits are in the Cookiecutter Template, that's what you'd maintain.
If you parameterise it, then you would pass the Python version into the call to cookiecutter.
Since this call takes place in the GitHub Template Repo's
setup.yml
workflow, you are maintaining the GitHub Template Repo.
It strikes me that you should seek to parameterise as much as possible, so I would opt for the second approach: the GitHub template repo.
I'm going to stop capitalising them now, you get the idea.
Self-service package templates
So let's put it into practice as a 'self-service' package template. I like this term as it's meant to describe a situation where
application owners can rapidly and reliably provision and maintain their application infrastructure without depending on IT operations teams.
OK it's pushing the definition a little, but at least I didn't say self-driving...
To start off, let's clarify the equivalence:
- Simon's Cookiecutter template repository is python-lib and mine is [py-pkg-cc-template][py-pkg-cc-template]
- Simon's GitHub template repository is python-lib-template-repository and mine is (going to be!) self-serve-py-pkg
To simplify things, I'm now going to refer to the cookiecutter template as the "source", since it's what gets pulled into the latter GitHub template repository.
We already have the first part, but it's worth comparing our implementations.
Simon's source repo has a .github/workflows directory containing one CI program to run,
on pushes, whose purpose is to regenerate a demo repo. That's more for demo-ing purposes,
so I'm going to skip it unless I start getting more experimental. It also has a README,
with usage guide (but I'm writing this blog which doubles as that),
a LICENSE, and a .gitignore of commonly commited files. I'm going to skip all of these and move on.
I've so far made my repo entirely from my own packages, so there's no need to include his license, but if you are then you should (the Apache-2.0 license requires preservation of copyright).
To set up the 2nd part begins with creating a new GitHub repo, checking the 'Template repository' setting, and cloning locally.
Simon's template repo is unlicensed, so I'm just going to adapt it and credit him here, leaving mine likewise unlicensed.
I'm starting with a blank repo, and in this one there are 3 YAML workflows:
publish publishes a PyPI package when a branch named release is created (I'm not doing this as discussed in the previous section)
test runs tests with pytest when pushed to (I've already got a CI workflow for testing so again I'm not using this)
setup is the good part. In order, it does the following:
-
First checks that the repo is not the template repo (if it is, none of the rest will run)
-
Checks out the GitHub repo HEAD ref (which was just updated by the push) on an
ubuntu-latestcontainer image -
Installs cookiecutter on the CI runner
-
Runs an (async) GitHub GraphQL API call in Node.js to retrieve the repo description, passing in two variables - the GitHub user (
$owner) and repo name ($name). It prints these out for debugging purposes.-
It has access to the user and repo names via an object containing the context of the workflow run, made available as a variable named
context. -
It has access to the GraphQL API via an octokit/rest.js client made available as a variable named
githubthanks to the github-script GitHub Action. -
From the looks of it, this Action should probably be upgraded from v4 to v6, the latest version.
-
The docs for the octokit/rest.js client mention that GraphQL queries require authentication, but it appears that is handled by GitHub itself here. (The README for this Action mentions something about automatic auth, fingers crossed...)
-
Check out the GraphQL API here in case you want to do more with it, and use the explorer here, e.g. to view all the fields on the
Repositoryobject type, the docs tell you to run:
query {
__type(name: "Repository") {
name
kind
description
fields {
name
}
}
}
⇣
assignableUsers, autoMergeAllowed, branchProtectionRules, codeOfConduct, codeowners, collaborators, commitComments, contactLinks, createdAt, databaseId, defaultBranchRef, deleteBranchOnMerge, deployKeys, deployments, description, descriptionHTML, discussion, discussionCategories, discussions, diskUsage, environment, environments, forkCount, forkingAllowed, forks, fundingLinks, hasIssuesEnabled, hasProjectsEnabled, hasWikiEnabled, homepageUrl, id, interactionAbility, isArchived, isBlankIssuesEnabled, isDisabled, isEmpty, isFork, isInOrganization, isLocked, isMirror, isPrivate, isSecurityPolicyEnabled, isTemplate, isUserConfigurationRepository, issue, issueOrPullRequest, issueTemplates, issues, label, labels, languages, latestRelease, licenseInfo, lockReason, mentionableUsers, mergeCommitAllowed, milestone, milestones, mirrorUrl, name, nameWithOwner, object, openGraphImageUrl, owner, packages, parent, pinnedDiscussions, pinnedIssues, primaryLanguage, project, projectNext, projects, projectsNext, projectsResourcePath, projectsUrl, pullRequest, pullRequestTemplates, pullRequests, pushedAt, rebaseMergeAllowed, ref, refs, release, releases, repositoryTopics, resourcePath, securityPolicyUrl, shortDescriptionHTML, squashMergeAllowed, sshUrl, stargazerCount, stargazers, submodules, tempCloneToken, templateRepository, updatedAt, url, usesCustomOpenGraphImage, viewerCanAdminister, viewerCanCreateProjects, viewerCanSubscribe, viewerCanUpdateTopics, viewerDefaultCommitEmail, viewerDefaultMergeMethod, viewerHasStarred, viewerPermission, viewerPossibleCommitEmails, viewerSubscription, visibility, vulnerabilityAlerts, watchers
query {
__type(name: "RepositoryOwner") {
name
kind
description
fields {
name
}
}
}
⇣
avatarUrl, id, login, repositories, repository, resourcePath, url
-
Takes the result from the previous step, extracts the repo name, description, username, and author's full name from the GitHub GraphQL API response (shown in bold in the list above) and uses these to parameterise the
cookiecuttercall.-
Simon's script does this with
pushdandpopdwhich I'd never come across but are similar togit stashandgit pop: he uses it to temporarily move to the/tmpfolder, generate the template files there, then returning to the original working directory, and moving the template files there (knowing they'll be in/tmp). -
It seems like the purpose of this manoeuvre is to 'step up a level' (since only the contents of the generated directory are desired at the root of the newly set up repo). Simon does this once for
/tmp/$REPO_NAME/*and then once for the.gitignoretoo (/tmp/$REPO_NAME/*). This I presume is since hidden ("dot") files are not included in*, If you specify these hidden files as.*then you inevitably hit the parent and self-reference (../and./) and get warnings. Neat enough, but be careful if you need more dot files. My source repo has pre-commit config YAML, ReadTheDocs config YAML, and a GitHub Actions workflow to copy over (which in fact I think Simon deliberately avoided here, since his GH Action was specifically for generating the demo from his source repo, whereas I'm not doing that so can copy it).
-
-
Lastly, the
setup.ymlis deleted in a slick act of self-destruction, before force-pushing to the same repo whose push triggered the workflow in the first place. This time, the push won't trigger the same workflow again, as its instructions just got deleted.
Item in the bagging area
This one file is all you need to adapt to get your own self-service Python package template repo.
-
First change the name of the repository checked from Simon's to yours (mine is
'lmmx/self-serve-py-pkg': note you must use single quotes here) -
Next upgrade the version of the checkout Action from v2 to v3.
-
This requires a GitHub Actions runner of 2.285.0+, and we seem to be getting 2.291 from reviewing recent jobs that have run on CI there.
-
Upgrade the github-script Action (which runs the GraphQL query) to v6. This doesn't affect
github.graphql, so I expect will be fine. -
Modify the
cookiecuttercall:
-
Change Simon's source repo (
simonw/python-lib) to yours (again, mine islmmx/py-pkg-cc-template) -
Change the call signature to match the one defined by your
cookiecutter.json(in the top level of your source repo). So mine is
{
"lib_name": "",
"description": "",
"hyphenated": "{{ '-'.join(cookiecutter['lib_name'].lower().split()).replace('_', '-') }}",
"underscored": "{{ cookiecutter.hyphenated.replace('-', '_') }}",
"github_username": "",
"author_name": "",
"email": "",
"year": ""
}
... which is the same approach as Simon's but with email and year (which I either need to hardcode or
figure out how to get from the GitHub API). On this point, returning to the GraphQL API Explorer,
I can see from the Explorer pane on the left hand side that the repositoryOwner (which I presume
is the type of the owner attribute of the Repository)
Note: the Explorer lets you step 'down' into the object's nested structure, which I think actually corresponds to cross-referencing 'up' ? Or at least is signified by three dots which I interpret as being 'up a level', I don't know: GraphQL is more intuited than understood for me... Essentially you can find extra details in this view though while doing
__typequeries to view the 'layout' in GraphQL, and add them back in to yourquerycommands to extract values.
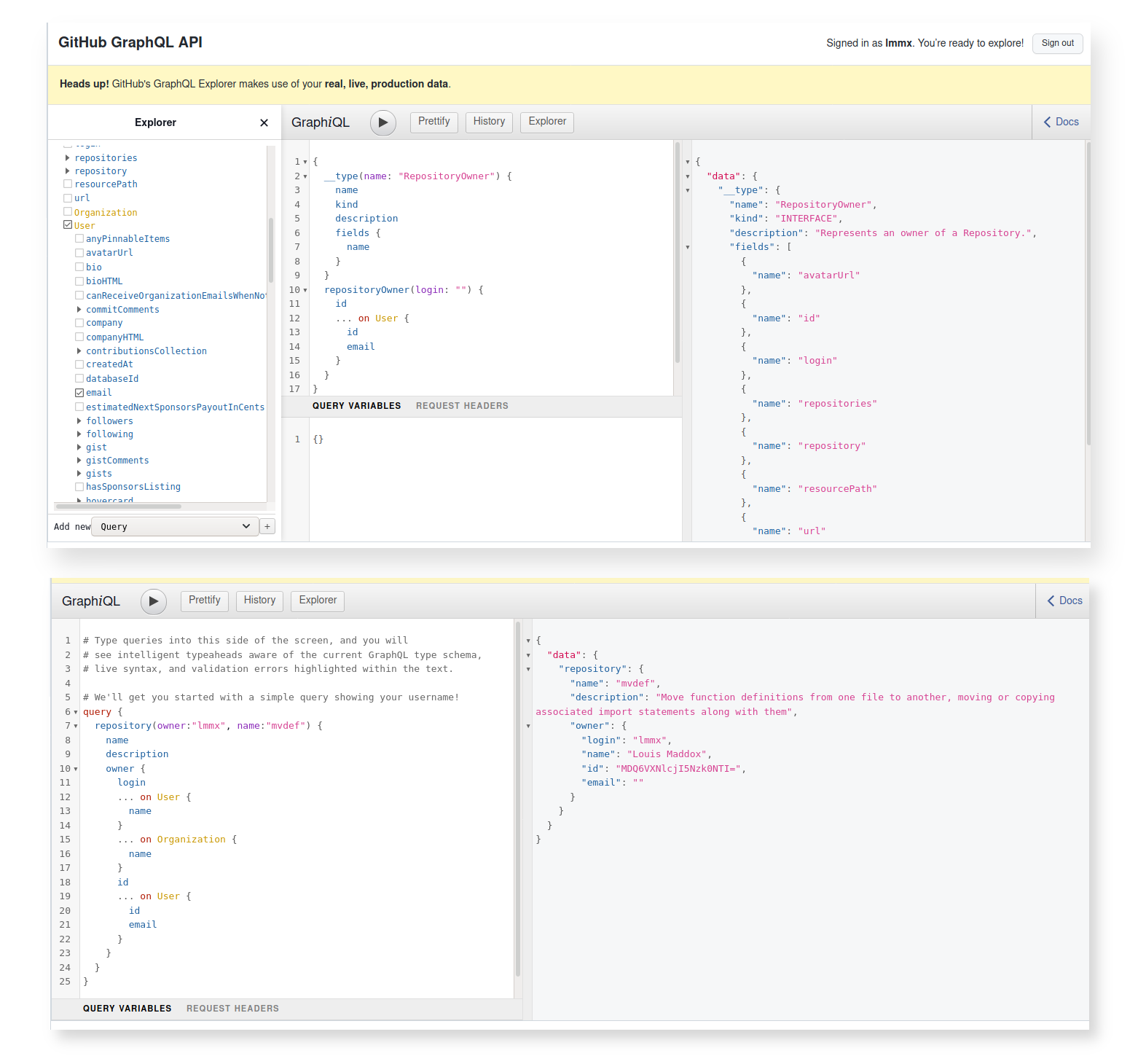
-
In this case, I wasn't able to figure out how to parameterise the
cookiecuttercall with my email from the GitHub API, which it turned out was because I set it to private (I think due to spam, probably by this exact mechanism lol). I guess you could hardcode it if you're using a private repo here (so nobody else would use it and accidentally put your email in one of their packages). -
Based on this, I decided to make the repo private (until I can figure out another way to parameterise this value).
-
I was able to figure out how to get the current year, since for a repo that just got created (and this workflow is triggered on that push) the value of the
createdAtfield will be the current date, and the first four characters of this date string will be the numeric year (now "2022").
year="$(echo $INFO | jq -r .repository.createdAt | cut -d\- -f 1)"
- Add all of the hidden files/directories to the root (working) directory
rather than just the
.gitignore. As already mentioned, for me this includes.pre-commit-config.yaml,.readthedocs.yaml, and a workflow and contributing doc at.github/*
Debugging permissions
Unfortunately, this initial attempt fell flat at the final step of force pushing, since the GitHub Actions bot apparently lacks the permissions on my repos. I confirmed that the same happens if I try to use Simon's template too:
Run stefanzweifel/git-auto-commit-action@v4
Started: bash /home/runner/work/_actions/stefanzweifel/git-auto-commit-action/v4/entrypoint.sh
INPUT_REPOSITORY value: .
INPUT_STATUS_OPTIONS:
INPUT_BRANCH value:
D .github/workflows/setup.yml
M README.md
Your branch is up to date with 'origin/main'.
INPUT_ADD_OPTIONS:
INPUT_FILE_PATTERN: .
INPUT_COMMIT_OPTIONS:
INPUT_COMMIT_USER_NAME: github-actions[bot]
INPUT_COMMIT_USER_EMAIL: github-actions[bot]@users.noreply.github.com
INPUT_COMMIT_MESSAGE: Initial library structure
INPUT_COMMIT_AUTHOR: lmmx <lmmx@users.noreply.github.com>
[main 564c03b] Initial library structure
Author: lmmx <lmmx@users.noreply.github.com>
7 files changed, 285 insertions(+), 98 deletions(-)
delete mode 100644 .github/workflows/setup.yml
create mode 100644 .gitignore
create mode 100644 LICENSE
rewrite README.md (99%)
create mode 100644 setup.py
create mode 100644 simon_w_template_demo_test/__init__.py
create mode 100644 tests/test_simon_w_template_demo_test.py
INPUT_TAGGING_MESSAGE:
No tagging message supplied. No tag will be added.
INPUT_PUSH_OPTIONS: --force
remote: Permission to lmmx/simon-w-template-demo-test.git denied to github-actions[bot].
fatal: unable to access 'https://github.com/lmmx/simon-w-template-demo-test/':
The requested URL returned error: 403
Reviewing the repo's /settings/actions, the section "Workflow permissions" seemed to indicate the
default is read-only, not read and write permissions when using the GITHUB_TOKEN
(which is what git-auto-commit-action must be doing internally).
The settings had a 'Learn more' link pointing to docs on
Modifying the permissions for the GITHUB_TOKEN:
You can modify the permissions for the
GITHUB_TOKENin individual workflow files. If the default permissions for theGITHUB_TOKENare restrictive, you may have to elevate the permissions to allow some actions and commands to run successfully.
so we don't need to change the repo settings [which don't exist before repo creation anyway]
if we change it for the workflow itself, by setting the permissions key:
You can use the
permissionskey in your workflow file to modify permissions for theGITHUB_TOKENfor an entire workflow or for individual jobs.
Except, it also says you can't do that:
You can use the
permissionskey to add and remove read permissions for forked repositories, but typically you can't grant write access.
...in which case I'm stumped on how to get this to work automatically.
Spoiler alert - the rest of this section is devoted to the litany of failures that followed this. Skip to the next section if you just want to find out what works.
The Action in question mentions in its README that:
Note that the Action has to be used in a Job that runs on a UNIX system (eg.
ubuntu-latest). If you don't use the default permission of the GITHUB_TOKEN, give the Job or Workflow at least thecontents: writepermission.
which suggests that you could set it at the workflow level...
I added the suggested permission to the YAML and got a new error (which is usually a good sign):
! [remote rejected] master -> master (refusing to allow a GitHub App to create or update workflow
`.github/workflows/master.yml` without `workflows` permission)
error: failed to push some refs to 'https://github.com/lmmx/self-serve-template-demo-test'
which makes sense, as we are deliberately rewriting the CI workflow, but the key workflows is not listed on the
permissions docs.
Only actions, which is similar?
I'd put the write permission on the job (setup-repo) not the entire workflow, so I wondered if it
meant that I needed to elevate it to the top level of the YAML file.
! [remote rejected] master -> master (refusing to allow a GitHub App to create or update workflow
`.github/workflows/master.yml` without `workflows` permission)
- When that didn't work, I tried adding the
actionspermission, andwrite-allfailing that, but no dice.
Failing that, my only guess was to instead change the condition from push to creation of the master branch,
and that way you wouldn't need to bother with changing the workflow YAML, with the only downside
that you'd have a leftover setup.yml and not get the cool self-deleting installer behaviour.
There's an example of this in the publish.yml workflow of Simon's
python-lib-template-repository, which means "when a branch named release is created":
on:
release:
types: [created]
So by changing the word release to master we can achieve the desired behaviour. This however also would mean giving up on moving the workflows into the workflow directory, and you'd need to do that manually, which is not so satisfyingly self-serviced.
TODO: this is wrong, "master" is not a valid event name apparently
I eventually realised that a template repo's settings will probably be copied when you generate from it, so I wouldn't need to worry about this after all. I can just change the settings on the template repo. Alas this wasn't true either.
Back to the drawing board
So this feature didn't work as advertised: in fact Simon documented it on his blog
This almost worked—but when I tried to run it for the first time I got this error:
![remote rejected] (refusing to allow an integration to create or update .github/workflows/publish.yml)It turns out the credentials provided to GitHub Actions are forbidden from making modifications to their own workflow files!
I can understand why that limitation is in place, but it’s frustrating here. For the moment, my workaround is to do this just before pushing the final content back to the repository:
sh mv .github/workflows .github/rename-this-to-workflowsI leave it up to the user to rename that folder back again when they want to enable the workflows that have been generated for them.
Except I don't think this was actually done in the code.
This constraint just means we need to have the same .github/workflows/ directory as in the source
repo. Maybe that's not actually such a hard constraint. I see 2 options now:
-
If your workflow doesn't involve the name of the package (or if it does, and you could be creative enough to figure out what this is programmatically) then there are no cookiecutter-templated files in the
.github/workflows/directory, so you can just duplicate them in the root directory of the template repo as they are in the source repo, and there'd be no error raised about the CI modifying that directory. -
The downside of this is that you are tied to an immutable
.github/workflowsdirectory, which must also contain thesetup.yml, so no neat self-deletingsetup.ymlfor you. Do not pass go, do not get bragging rights about how cool your CI is.- The other downside is that you double your maintenance burden: whenever you edit your source repo's workflow(s), you'd need to check it matches the template repo's.
-
If your workflow does involve the name of the package, then you can't cheat by duplicating the finished workflow in the template repo, because the cookiecutter template tags wouldn't be filled in (and you can't edit them due to no
workflowspermission as discussed). What you could do in this case would be to run it anyway, switch on the setting for write permission then let the CI run, then switch the setting off again (all manually). So rather than 1 click, it'd be an extra 2 clicks. In fact, you might even want to turn off the push trigger and just use theworkflow_dispatchtrigger (i.e. the "Run workflow" on the Actions page), since the first push wouldn't work due to the aforementioned default read-only repo settings for Actions. -
The major upside here is that you keep the 'self-service' approach of a self-deleting setup workflow at only 3 steps extra:
- Turn on write permissions in the repo's Actions settings
- Click the Run button on the Actions page
- Turn off write permissions in the repo's Actions settings
-
No extra maintenance burden, and otherwise works as intended.
Note that this manual approach also allows you to pass in extra values! As documented over on the GitHub blog post announcing the feature in 2020,
In addition, you can optionally specify
inputs, which GitHub will present as form elements in the UI. Workflow dispatch inputs are specified with the same format as action inputs.
This would let you fill in extra values like email address rather than hardcoding it privately, or any other customisation.
...still no dice. Changing the setting does not permit an Action to modify the workflows directory.
My only other idea would be to use GitLab, since I've already set up a personal access token for CI/CD
import sync there, and with that I should be able to run custom workflows in a .gitlab-ci.yml file
which might then be able to overwrite a repo.
-
The GitLab setup would require secrets, and to avoid setting up secrets on every run you'd only put them in the original template repo's GitLab mirror: the
self-serve-py-pkgmirror on GitLab (ostensibly a test runner, but in this case used for packaging automation). -
You could then trigger that GitLab CI workflow with a webhook (fired off from the default CI job of the generated template on GitHub CI)
-
The triggered GitLab CI would need to retrieve a payload sent via POST request to the webhook (
TRIGGER_PAYLOAD, see docs) with the repo name. -
Provided this webhook was triggered after the templated repo was pushed to, the ensuing follow-up push would be protected from prematurely overwriting the
.github/workflowsdirectory.
But I do wonder at this point: surely we can keep it all within GitHub? If the way GitLab is going to push to GitHub is through using a Personal Access Token triggered by a webhook, then surely I can authenticate a GitHub workflow with a PAT and achieve the same effect without mixing providers?
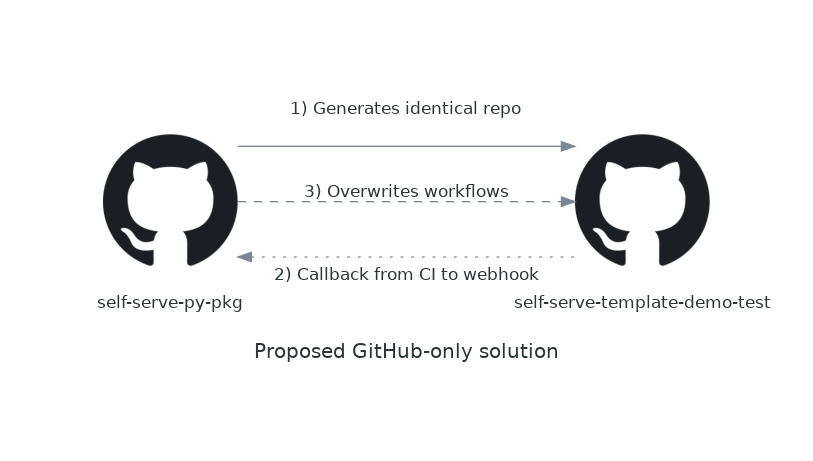
So far we've got step 1 of this prototyped out: we can generate a repo from the self-serve-py-pkg
template repo and have it run a CI workflow. The next step we need is to include a webhook callback,
which is just a POST request which can be done with curl in the workflow script, but before that
we need to set up a GitHub webhook.
GitLab provides so-called "pipeline triggers" which I don't think GitHub has a version of... This allows you to kick off a CI job on one repo from the CI job of another.
According to this forum post:
You’ll need to set up a personal access token as a secret in the library’s repository
by which it's meant the sender repository (not the receiver). This is not an acceptable solution, because the sender repository is going to be the one generated from the repo (and secrets are set manually, not copied over during template generation, so this sender repo cannot be expected to have secrets).
Unfortunately, if there's no way to accept an event on another repository as the trigger then this does in fact rule out GitHub, and GitLab is the only way to do this. Yay, awkward!
- Another confirmation of this approach is given here, note it again requires the PAT to be stored as a secret on the 'sender repo' rather than the receiver
Reusable workflows and repository dispatches
While entering the part of the development cycle formally known as "desperation",
I came across the workflow_call event, and its associated concept of
reusable workflows
While I initially assumed workflow_call would be restricted to workflows in the same repo,
thereby ruling out use to trigger one repo's from another's,
it turned out that the requirements are actually:
A reusable workflow can be used by another workflow if either of the following is true:
- Both workflows are in the same repository.
- The called workflow is stored in a public repository, and your organization allows you to use public reusable workflows.
When presented with this constraint of using a public GitHub template repo, I realised that if you stored your email and any other personal values being provided to cookiecutter as a secret, you could make the repo public without a problem (this was already possible in hindsight).
I then came across the repository_dispatch event, which seems like an exact match
for what GitLab called pipeline triggers. This appears to obviate my last resort of a
GitHub-to-GitLab approach.
How to send a repository_dispatch event
The docs have a page on creating a repository dispatch event with both a curl and JS option. The JS approach is nicer to read, and I'm optimising for something nicely maintainable and adaptable (you could surely switch to curl to optimise speed instead).
The example given includes authentication, and is essentially in the form of:
await github.request(`POST /repos/${owner}/${repo}/dispatches`, {
owner: owner,
repo: repo,
event_type: 'on-demand-test',
})
You can equivalently and more succinctly use the pre-authenticated API library as:
await github.rest.repos.createDispatchEvent({
owner: owner,
repo: ss_repo_name,
event_type: "on-demand-test"
});
However note that a PAT must be configured for this to succeed.
- We can get a pre-authenticated
Octokit.jsclient using the Action Simon used in his template repo'ssetup.yml, actions/github-script - You can also pass a
client_payloadin your request (presumably likewise in the REST endpoint method). I expect I will want to pass through the GitHub user and repo name (which to clarify will be the repo name of the created repo, or maybe thecontextwill suffice for this).
There's a good blog post on how a repository dispatch works in practice
here,
which notes that the event_type you specify in your payload becomes the value of
context.payload.action when received (and is just a string, e.g. the author there uses "my-event").
Another good blog post here.
If, instead, I was to use the workflow call approach, I'd get this payload populated with the event context, but it's less clear to me whether that would remove the necessary distinction between sender/receiver repos which I need to preserve...
- See this reusable workflow and the workflow it got used in for an example. Note that there's annotations for input type and whether they're required/optional.
However, when I tried this, all I could achieve was the error:
Resource not accessible by integration
There's a catch-22 in regards to automation here:
- The self-serve repo cannot detect when a new repo is generated from it
- A newly generated repo does not have any secrets
- A newly generated repo cannot send a repository dispatch event back to the self-serve repo it came from without elevated permissions (i.e. a Personal Access Token)
- The only way to provide a PAT to a newly generated repo is via secrets
- The only way to set secrets on a new repo is to do so manually
So in short, you can't automate self-serve package templating with template repos and Cookiecutter within the constraint of a GitHub Actions-only solution.
Designing a GitHub-to-GitLab approach
As a last resort, I suspect that GitLab could achieve the desired outcome because you don't need elevated permissions to trigger a workflow on another repo's GitLab CI. In fact, it's encouraged:
You can trigger a pipeline for a branch or tag by generating a trigger token and using it to authenticate an API call. The token impersonates a user’s project access and permissions.
This is the killer feature of GitLab that led me to use it for generating my website, the way that tokens assume a user's project access and permissions.
Here's the architecture that this capability enables:
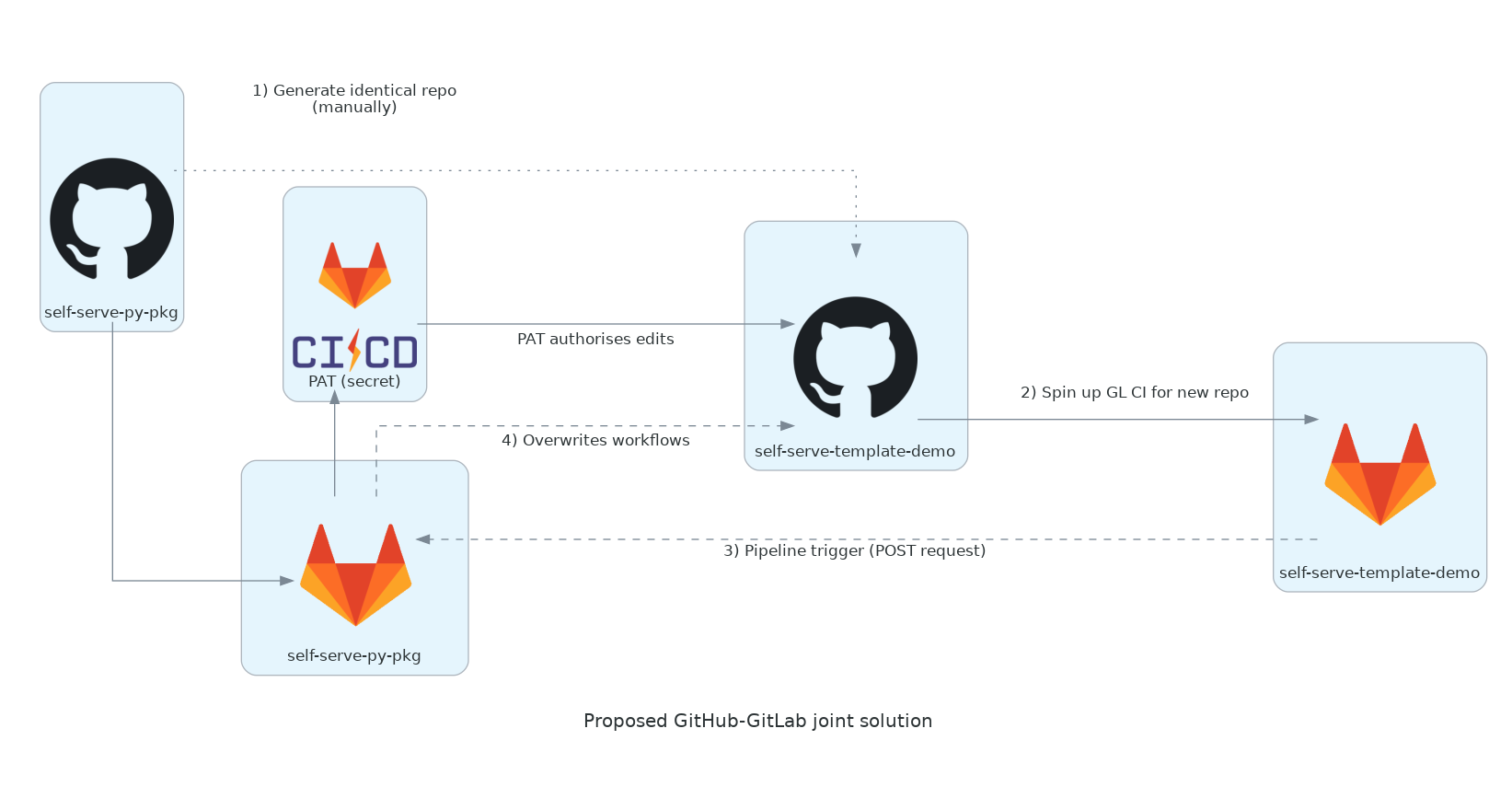
- When a new repo is created (and in the case of template repos, immediately pushed to),
if it has a GitLab CI config file
.gitlab-ci.yml, and if GitLab is set up as an app for the user's GitHub account, - the repo will be 'mirrored' to the same user's GitLab account, and CI workflows will begin there.
- We can write a GitLab CI workflow job that sends a POST request to the 'pipeline trigger' endpoint for the GitLab CI workflow of another repo: the mirror of the 'parent' template repo.
- If we store a GitHub Personal Access Token as a GitLab CI/CD secret of this 'parent' repo's GitLab mirror, then when the pipeline trigger launches a CI runner, it will be authorised to write to the GitHub repo [as long as the PAT is appropriately scoped and the repo being written to is accessible, most simply if both repos are on the same account].
GitHub is fully integrated with this CI 'mirroring' to GitLab, so we can see the results of the GitLab CI checks within GitHub (ticks and crosses display pass/fail status for each job as for those in GitHub Actions).
This seems quite a daunting undertaking at first, but sketching out the prototype's
architecture diagram and numbering the steps lets us start at the beginning, with GitLab CI config
file in the template repo (self-serve-py-pkg).
We want this GitLab config to do just one thing: to overwrite the workflows directory of the repo which triggers it (which we receive as the event from the pipeline trigger).
I've written two types of GitLab CI before: super-simple pages jobs to generate websites, and more complex Debian-deployed jobs acting as serverless microservices.
The default runner image on GitLab is Ruby (as in it ships with the programming language Ruby), so if you want to run Python in your image you switch to another like Debian 11 Slim.
Debian 11 is a.k.a. "Bullseye", "Slim" means it's a minimal Linux build
Here's how you POST to a pipeline trigger (which we want to run in the repo generated from the template repo):
trigger_templater:
stage: deploy
script:
- curl -X POST -F token=PIPELINE_TRIGGER_TOKEN_GOES_HERE -F ref=master
https://gitlab.com/api/v4/projects/PROJECT_ID_GOES_HERE/trigger/pipeline
That's the entire file, not just a snippet!
Next, here's (roughly) how you write a file in a git-cloned GitHub repo then push the changes back (which we want to run in the GitHub template repo's GitLab mirror):
before_script:
- eval "$(ssh-agent -s)"
# Following: https://serverfault.com/questions/856194/securely-add-a-host-e-g-github-to-the-ssh-known-hosts-file
- GITHUB_FINGERPRINT=$(ssh-keyscan -t ed25519 github.com | tee github-key-temp | ssh-keygen -lf -)
- GITHUB_EXPECTED_FINGERPRINT="256 SHA256:+DiY3wvvV6TuJJhbpZisF/zLDA0zPMSvHdkr4UvCOqU github.com (ED25519)"
# From: https://docs.github.com/en/authentication/keeping-your-account-and-data-secure/githubs-ssh-key-fingerprints
- if [ ! "$GITHUB_FINGERPRINT" = "$GITHUB_EXPECTED_FINGERPRINT" ]; then echo "Error - SSH fingerprint mismatch" 1>&2 && exit 25519; fi
- mkdir -p ~/.ssh # This shouldn't be necessary but getting an error that "file/dir. doesn't exist" on next line
- cat github-key-temp >> ~/.ssh/known_hosts && rm github-key-temp
- ssh-add <(echo "${SSH_priv_key_GitHub}" | base64 --decode)
- git config --global user.email "${git_email}"
- git config --global user.name "${full_name}"
stages:
- WRITE_TO_REPO
overwriting:
stage: WRITE_TO_REPO
script:
- git clone git@github.com:OWNER/REPO_NAME.git
- cd REPO_NAME
- echo "foo
bar
baz" > .github/workflows/NEW_WORKFLOW_NAME.yml
- git add .github
- git commit -m "Added NEW_WORKFLOW_NAME.yml"
- git push origin master
This example is adapted from a tried and tested config for my website engine quill
The CI/CD Variables (secrets) you need to set for the above are:
full_name(protected)git_email(protected and masked)SSH_priv_key_GitHub(protected and masked)
Here protected refers to running only on protected branches and tags, and masked refers to whether the string will be redacted with asterisks from CI logs
We're going to get around the first two of these variables by using environment variables and POST request payload info instead.
- The GitHub SSH private key comes from here
There's one aspect that we've forgotten though, which is that
both of the GitLab workflows will have to be in the same repo.
For GitHub Actions workflows that's easy enough as you put them in the
.github/workflows/ directory with one workflow per YAML file (named however you like).
For GitLab though the file sits in the top level of the repo, named .gitlab-ci.yml:
The unit of work is a job, and a job has a
stagedefined, and (optionally) you can list the order ofstages.
In GitHub Actions, we would control the repos that a workflow job ran on with if:
jobs:
trigger-ci:
if: ${{ github.repository != 'lmmx/self-serve-py-pkg' }}
This would only run when a new repo was generated from the template repo, and not when the template repo was pushed to.
In GitLab, you use the rules keyword instead, which accepts
an array of rules defined with: -
ifto specify when to add a job to a pipeline -changesby checking for changes to specific files -existsto run a job when certain files exist in the repository -allow_failureto allow a job to fail without stopping the pipeline -variablesto define variables for specific conditions -whento configure the conditions for when jobs run
- The docs give some common examples here
- The rules are evaluated by using predefined variables or custom variables.
The closest equivalent of github.repository in GitLab is probably CI_REPOSITORY_URL.
To review all of them during development, we can just dump the os.environ dict to CI logs from Python:
- python3.9 -c "from os import environ as env; from pprint import pprint as pp; pp(dict(env));"
So to start easy, let's create a new .gitlab-ci.yml in the template repo and build up from there:
image: "python:3.9"
before_script:
- python3.9 -c "from os import environ as env; from pprint import pprint as pp; pp(dict(env));"
stages:
- WRITE_TO_REPO
overwriting:
stage: WRITE_TO_REPO
script:
- echo "Testing..."
- mkdir "test_dir"
- echo "foo
bar
baz" > test_dir/my_new_file
- cat test_dir/my_new_file
Upon trying this though I (re-)discovered that repository mirroring is not automatic. You need to manually create a GitLab mirror, which rules out the approach I outlined above (specifically step 2, where GitLab CI is spun up for the new repo automatically when a repo is generated from the template repo).
This is fine, and in fact highlights a redundancy in our approach: the generated repo's GitHub Actions CI serves no purpose. Maybe another way of visualising these architectures might've made that clearer at the drawing board.
- Remove step 2
- Go straight to step 3: send the POST request to trigger the pipeline from GitHub Actions CI on the newly generated repo.
This also solves any issue about handling GitLab CI rules, as we no longer have to constrain where the GitLab CI runs. Now the GitLab CI only runs on the template repo, and the GitHub CI only runs on the template-generated repo.
Preliminary steps
- Generate a Personal Access Token with
reposcope and an informative name (mine is "GitLab CI/CD import sync repo mirroring (template repos)"). -
I suggest making a new one here, not reusing one from an old project if you somehow have it, so when you periodically regenerate your PAT (a security measure known as "rotating" the token, in case it leaked out unbeknownst to you) then you won't need to update multiple repo mirror integrations. You will also be naming your PAT with an indication of the project you're using it with, whereas using one for multiple projects would leave you unsure if you'd updated them all when rotating.
-
Set up GitLab repository mirroring on the GitHub template repo (instructions via):
- Run CI/CD for external repository
- Click GitHub then enter a Personal Access Token (recommended over "Repo by URL" which involves entering your password)
- Once added, if you don't see anything listed on the left hand menu under CI/CD >
Pipelines, you may need to go to click on 'Run pipeline' to get it set up (failing that try
the Editor which will show a spinning wheel while still 'looking' for the pipeline).
After this, it should run the CI on each push event automatically, and you can see all runs under
CI/CD > Jobs.
- Note: you must have at least one job that can run when 'Run pipeline' is clicked. A job that only runs on trigger events will not run on manual dispatch (button clicks on the website) and you'll see an error that there are no jobs to run as a pipeline.
- If you don't set up a pipeline now, then your request to the pipeline trigger later will give a 404 error.
-
Make a GitHub SSH key for use in the GitLab CI (for permission to overwrite the newly generated repo).
- Add the public key to your GitHub account here (review existing keys here). I called mine "GitHub template repo (self-serve-py-pkg) mirror editor".
- Store the private key in the template repo's GitLab mirror's secrets (which GitLab calls 'Variables', under 'CI/CD' settings on the repo), naming it `SSH_priv_key_GitHub``. You must base64 encode and remove newlines from the key to fit the requirements for masked secrets
MAKE SURE YOU MASK YOUR PRIVATE SSH KEY!
If you don't, it can potentially show up in the logs, and anyone who finds them will be able to p0wn your GitHub account.
Note that we won't
ssh-addthis on our local system, as it's only to be used on the GitLab CI.
# When prompted, save the file under ~/.ssh/id_ed25519_github_template_ci
ssh-keygen -t ed25519 -C "youremail@here.com"
# Public key for GitHub account
xclip -selection clipboard < ~/.ssh/id_ed25519_github_template_ci.pub
# Private key for GitLab repo secret
cat ~/.ssh/id_ed25519_github_template_ci | base64 | tr -d "\n" | xclip -sel clip
See my notes on generating SSH keys on Linux or more detail in the official GitHub guide
- Set up a pipeline trigger on the repo mirror that we can use to kick off the GitLab CI pipeline from our generated repo(s). This is under Settings > CI/CD > Pipeline triggers. Name the trigger something informative (but since every template will use the same trigger it's not too important). I called mine "Set up templated repo" (because that's what the pipeline launched will do).
The button to add a new trigger is accompanied by helpful usage examples, in particular this one for a YAML-friendly
curl:
- "curl -X POST --fail -F token=TOKEN -F ref=REF_NAME https://gitlab.com/api/v4/projects/MY_PROJECT_ID_HERE/trigger/pipeline"
however note that the
--failflag will hide the error message (and just show the status code of the response), so remove this while debugging.
i.e. in GitHub Actions it'll be:
curl -X POST \
--fail \
-F token=TOKEN \
-F ref=REF_NAME \
-F "variables[CUSTOM_CI_VARIABLE_HERE]=true" \
https://gitlab.com/api/v4/projects/MY_PROJECT_ID_HERE/trigger/pipeline
Note that this token can be used to trigger your pipeline by anyone! It has to be public because the template repo is public, and it has to be stored in there as the repo we generate from the template repo has no secrets (requiring them would break the automation). We're going to add sufficient checks and balances that this won't be any sort of security risk, but used in the wrong way it could be: use with care.
Building a joint GitHub/GitLab CI solution
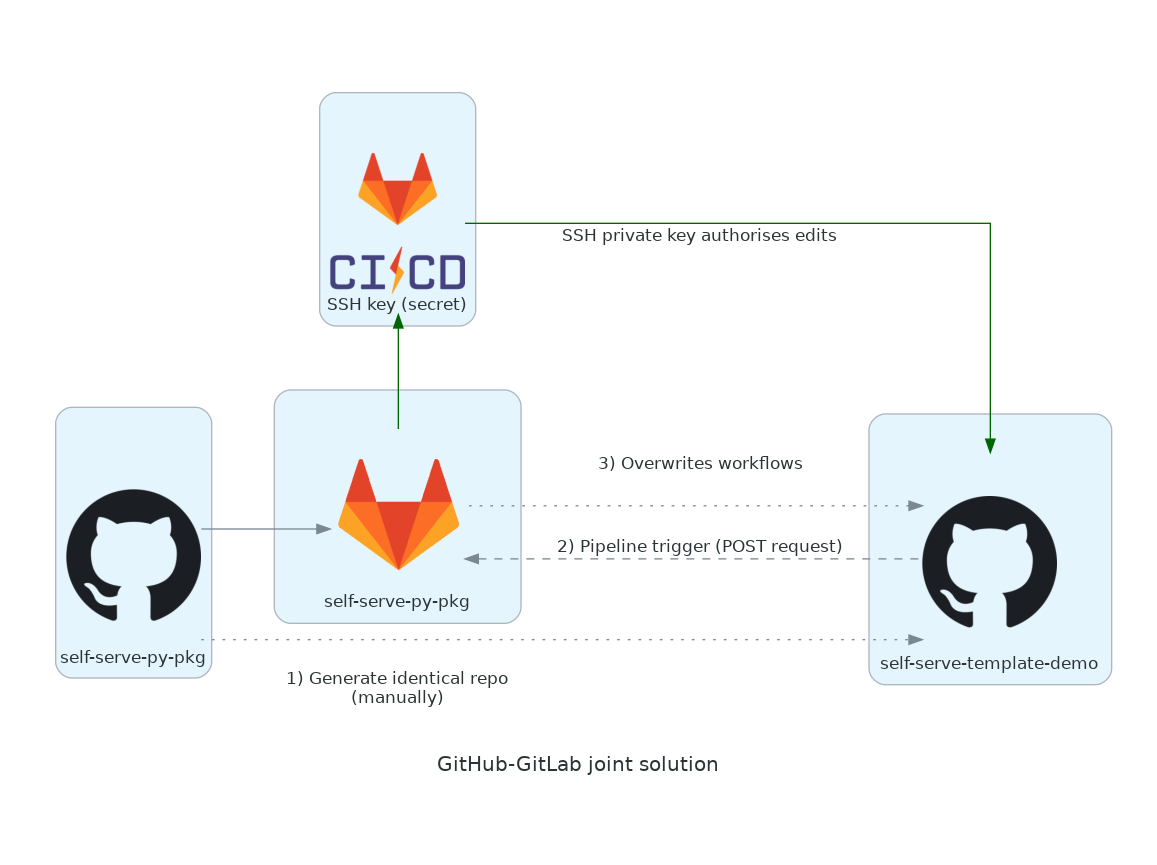
Our new solution goes:
- When a new repo is created from a template repo and therefore initially pushed to,
the GitHub Actions workflow gated by a check on the
github.repositoryvariable will run. - This workflow will send a POST request to the 'pipeline trigger' endpoint of the GitLab repo that was set up manually beforehand to mirror the 'parent' template repo that was just generated from. We can pass in a payload with the request with the repo name.
- Using the GitHub SSH private key secret,
the GitLab CI pipeline triggered by the POST request
can write to the GitHub repo that sent it the request.
This corresponds to the self-deleting
setup.ymlworkflow in Simon's attempt.
The GitLab CI/CD workflow in step 3 is always .gitlab-ci.yml and running the one drafted above
(printing the environment variables from Python) shows that there are 3 environment variables we can
use to register our GitHub username:
'CI_PROJECT_NAME': 'self-serve-py-pkg',
'CI_PROJECT_NAMESPACE': 'lmmx',
'CI_PROJECT_PATH': 'lmmx/self-serve-py-pkg',
'CI_PROJECT_ROOT_NAMESPACE': 'lmmx',
'CI_PROJECT_URL': 'https://gitlab.com/lmmx/self-serve-py-pkg',
'GITLAB_USER_LOGIN': 'lmmx',
Rather than hardcoding my own username, I can therefore refer to:
CI_PROJECT_NAMESPACEorCI_PROJECT_ROOT_NAMESPACEorGITLAB_USER_LOGINas the username,CI_PROJECT_NAMEas the repo name,CI_PROJECT_PATHas theowner/repopathCI_PROJECT_URLas the mirror URL and replacing the root domain with "github.com" gives the GitHub URL
These are all potentially useful ingredients to note down.
We also need to add a condition to do with the payload from the POST request, so next let's look at
the trigger.yml GitHub workflow (step 2). It's quite long so I'll add the output of each step in between:
name: Send a pipeline trigger back to the originating template repo's GitLab mirror
on:
push:
jobs:
trigger-ci:
if: ${{ github.repository != 'lmmx/self-serve-py-pkg' }}
runs-on: ubuntu-latest
steps:
- name: Greet
run: |
echo "Hello from $OWNER this is $REPO"
env:
OWNER: ${{ github.repository_owner }}
REPO: ${{ github.repository }}
Hello from lmmx this is lmmx/self-serve-demo
- uses: actions/github-script@v6
id: fetch-repo-and-user-details
with:
script: |
const query = `query($owner:String!, $name:String!) {
repository(owner:$owner, name:$name) {
createdAt
name
description
owner {
login
... on User {
name
}
... on Organization {
name
}
}
}
}`;
const variables = {
owner: context.repo.owner,
name: context.repo.repo
}
const result = await github.graphql(query, variables)
console.log(result)
return result
{ repository: { createdAt: '2022-MM-DD-SS.XYZ', name: 'self-serve-demo', description: 'This is a test repo :-)', owner: { login: 'lmmx', name: 'Louis Maddox' } } }
- name: Inform and trigger pipeline
run: |
export GH_REF=$(echo $GH_REF_HEAD | cut -d\/ -f 3) # e.g. refs/heads/master --> master
export GH_REPO_NAME=$(echo $INFO | jq -r '.repository.name')
export GH_AUTHOR_NAME=$(echo $INFO | jq -r '.repository.owner.name')
export GH_USERNAME=$(echo $INFO | jq -r '.repository.owner.login')
export GH_DESCRIPTION=$(echo $INFO | jq -r '.repository.description')
export GH_YEAR_REPO_CREATED=$(echo $INFO | jq -r '.repository.createdAt' | cut -d\- -f 1)
echo "Hello from $GH_AUTHOR_NAME a.k.a. $GH_USERNAME"
echo "This is $GH_REPO_NAME created in $GH_YEAR_REPO_CREATED on branch $GH_REF"
echo "More details: $GH_DESCRIPTION"
curl -X POST --fail -F token=$PIPELINE_TRIGGER \
-F ref=$GH_REF \
-F "variables[GH_OWNER]=$GH_OWNER" \
-F "variables[GH_REPO]=$GH_REPO" \
-F "variables[GH_REPO_URL]=$GH_REPO_URL" \
-F "variables[GH_REF]=$GH_REF" \
-F "variables[GH_REPO_NAME]=$GH_REPO_NAME" \
-F "variables[GH_AUTHOR_NAME]=$GH_AUTHOR_NAME" \
-F "variables[GH_USERNAME]=$GH_USERNAME" \
-F "variables[GH_DESCRIPTION]=$GH_DESCRIPTION" \
-F "variables[GH_YEAR_REPO_CREATED]=$GH_YEAR_REPO_CREATED" \
https://gitlab.com/api/v4/projects/$PROJECT_ID/trigger/pipeline
env:
INFO: ${{ steps.fetch-repo-and-user-details.outputs.result }}
PIPELINE_TRIGGER: c608274746d1da1521ace78909c6e6
PROJECT_ID: 36180497
GH_OWNER: ${{ github.repository_owner }}
GH_REPO: ${{ github.repository }}
GH_REPO_URL: ${{ github.repositoryUrl }}
GH_REF_HEAD: ${{ github.ref }}
Hello from Louis Maddox a.k.a. lmmx This is self-serve-demo created in 2022 on branch master More details: This is a test repo :-)
This also triggered the GitLab pipeline, which again dumped out the environment variables,
within which were OWNER, REPO, REPO_NAME, DESCRIPTION, GITHUB_USERNAME and AUTHOR_NAME
which had been passed through from the GitHub Actions trigger.yml workflow.
Once the GitHub side was figured out, the GitLab side came together pretty quickly.
The GitLab CI config defined two jobs with mutually exclusive rules: one that only ran
when the source was a trigger event and one that didn't run on a trigger event
(required for the CI to run upon setup). The latter just printed out "Nothing to do...",
but as mentioned it had to be there (this is known as a 'no-op').
I also changed the before_script section that I'd used to debug the GitHub SSH key setup into the
script block before the main work of sending git commits and overwriting the workflows. This
prevented it from running in the 'no-op' CI job (which'd be a waste of time).
As an added safeguard, since SSH keys are highly sensitive,
I manually excluded files with the .pem extension from the git staging area.
default:
tags: [docker] # Runners will pick the job up faster (not leave it pending)
image: "python:3.9"
stages:
- INITIALISED
- WRITE_TO_REPO
greeting:
stage: INITIALISED
rules:
- if: $CI_PIPELINE_SOURCE != "trigger"
script:
- echo "Nothing to do ..." # Do not delete this job, needed to run initial pipeline
overwriting:
stage: WRITE_TO_REPO
rules:
- if: $CI_PIPELINE_SOURCE == "trigger"
script:
#- python3.9 -c "from os import environ as env; from pprint import pprint as pp; pp(dict(env));"
# Uncomment to debug
- python3.9 -c "assert '$GH_REPO_NAME' != '', 'Stopping early because env. var. \$GH_REPO_NAME is empty'"
- python3.9 -c "assert '$GH_USERNAME' == 'lmmx', 'Stopping early because env. var. \$GH_USERNAME is not lmmx'"
# Basic input validation
- python3.9 -m pip install cookiecutter
- eval "$(ssh-agent -s)"
# Following: https://serverfault.com/questions/856194/securely-add-a-host-e-g-github-to-the-ssh-known-hosts-file
- GITHUB_FINGERPRINT=$(ssh-keyscan -t ed25519 github.com | tee github-key-temp | ssh-keygen -lf -)
- GITHUB_EXPECTED_FINGERPRINT="256 SHA256:+DiY3wvvV6TuJJhbpZisF/zLDA0zPMSvHdkr4UvCOqU github.com (ED25519)"
# From: https://docs.github.com/en/authentication/keeping-your-account-and-data-secure/githubs-ssh-key-fingerprints
- if [ ! "$GITHUB_FINGERPRINT" = "$GITHUB_EXPECTED_FINGERPRINT" ]; then echo "Error - SSH fingerprint mismatch" 1>&2 && exit 25519; fi
- mkdir -p ~/.ssh # This shouldn't be necessary but getting an error that "file/dir. doesn't exist" on next line
- cat github-key-temp >> ~/.ssh/known_hosts && rm github-key-temp
- ssh-add <(echo "${SSH_priv_key_GitHub}" | base64 --decode | tr -d "\r") 2>&1 | cut -d\( -f 1
# So that the key name isn't printed, in brackets, but we still see the message if an error occurs like
# https://stackoverflow.com/questions/55223622/
- git show-ref
# git refs in the initial working directory (the git repo of the runner)
- git config --global user.email "${GITLAB_USER_EMAIL}"
- git config --global user.name "${GITLAB_USER_NAME}"
# Relies on email and name being the same as for GitHub
- GIT_REPO_SSH_URL="git@github.com:$GH_USERNAME/$GH_REPO_NAME.git"
- git clone -b $GH_REF --depth 1 $GIT_REPO_SSH_URL
# https://stackoverflow.com/questions/1911109/how-do-i-clone-a-specific-git-branch
# --depth flag implies --single-branch (https://git-scm.com/docs/git-clone)
# Move out of repo
- pushd /tmp
- cookiecutter gh:lmmx/py-pkg-cc-template --no-input
lib_name="$GH_REPO_NAME"
description="$GH_DESCRIPTION"
github_username="$GH_USERNAME"
author_name="$GH_AUTHOR_NAME"
email="$GITLAB_USER_EMAIL"
year="$GH_YEAR_REPO_CREATED"
- popd
# Move back to repo
- mv $GH_REPO_NAME/.git /tmp/$GH_REPO_NAME/
# Move git subdirectory of template-generated repo into the generated package (so it becomes the new repo)
- cd /tmp/$GH_REPO_NAME/
- ls -a
# - git remote set-url origin $GIT_REPO_SSH_URL
# The pipeline is a git repo (for the commit that was last pushed),
# so the clone is a submodule and therefore needs to have a remote added to be able to push
# https://stackoverflow.com/questions/8372625/git-how-to-push-submodule-to-a-remote-repository
- git add --all ':!*.pem'
- git commit -m "Cookiecutter template auto-generated by $CI_PROJECT_PATH"
-m "CI job URL '$CI_JOB_URL'"
-m "CI job started at $CI_JOB_STARTED_AT"
- git show-ref
# git refs in the final working directory (the git repo of the new package, via the template-generated repo)
- git push origin $GH_REF
# The repo will now contain only what was generated from the cookiecutter template
et voilà!
As explained at the start, the decision of where to place the maintenance burden was to keep it out
of this part, and in the template itself. That means I didn't want to manually add particular hidden
files/directories like .pre-commit-config.yaml, .github workflows etc. but instead just pull in
the template. Any changes to the template would otherwise require changes to this CI automation,
which makes small changes require twice the number of files to edit and that kind of imposition
immediately starts to put you off iterating on anything in fear of it breaking.
While developing I left a call just before the git push to:
- python3.9 -c "raise ValueError('Halt early')"
which prevented a few near-misses with committing .pem SSH keys. Be very careful with this stuff!
After reviewing the security principles involved and potential failure modes, I'm happy to use this
myself and recommend it for others. My setup will only work for me because I hardcoded my template
in (lmmx/py-pkg-cc-template). I didn't use a variable for this, as the endpoint is public so
CI variables can be injected by anyone with the URL.
A common slip-up is passing in empty strings, which when used in paths give the parent directory. I validate that this isn't happening at the start, again for security.
Potentially over-cautiously, I also added a check that the username is mine, lmmx,
as otherwise I can vaguely see a scenario where someone permits access to my account to edit their
repo (I think that's doable?) and then uses my credentials to generate things for them,
or worse to somehow leak my SSH key into their possession.
You can keep this endpoint private by adding the pipeline trigger ID to your secrets, but here I tried to keep the config simple: the only secret is the GitHub SSH key for write access.
Last but not least I erased the logs from runs where I'd dumped out the environment variables, just for good measure.
Pics or it didn't happen
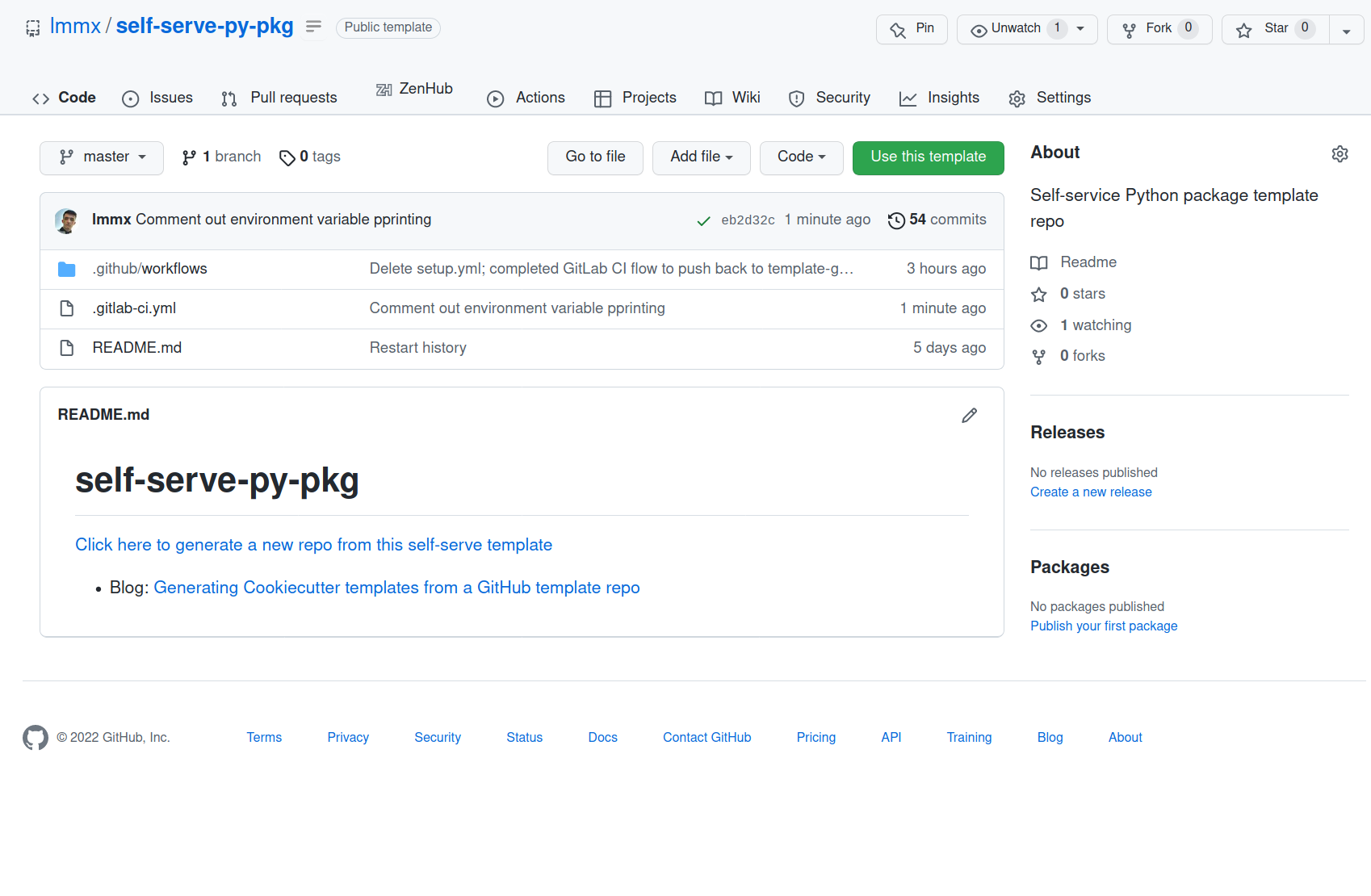
Before: this is the template with the big green Use this template button
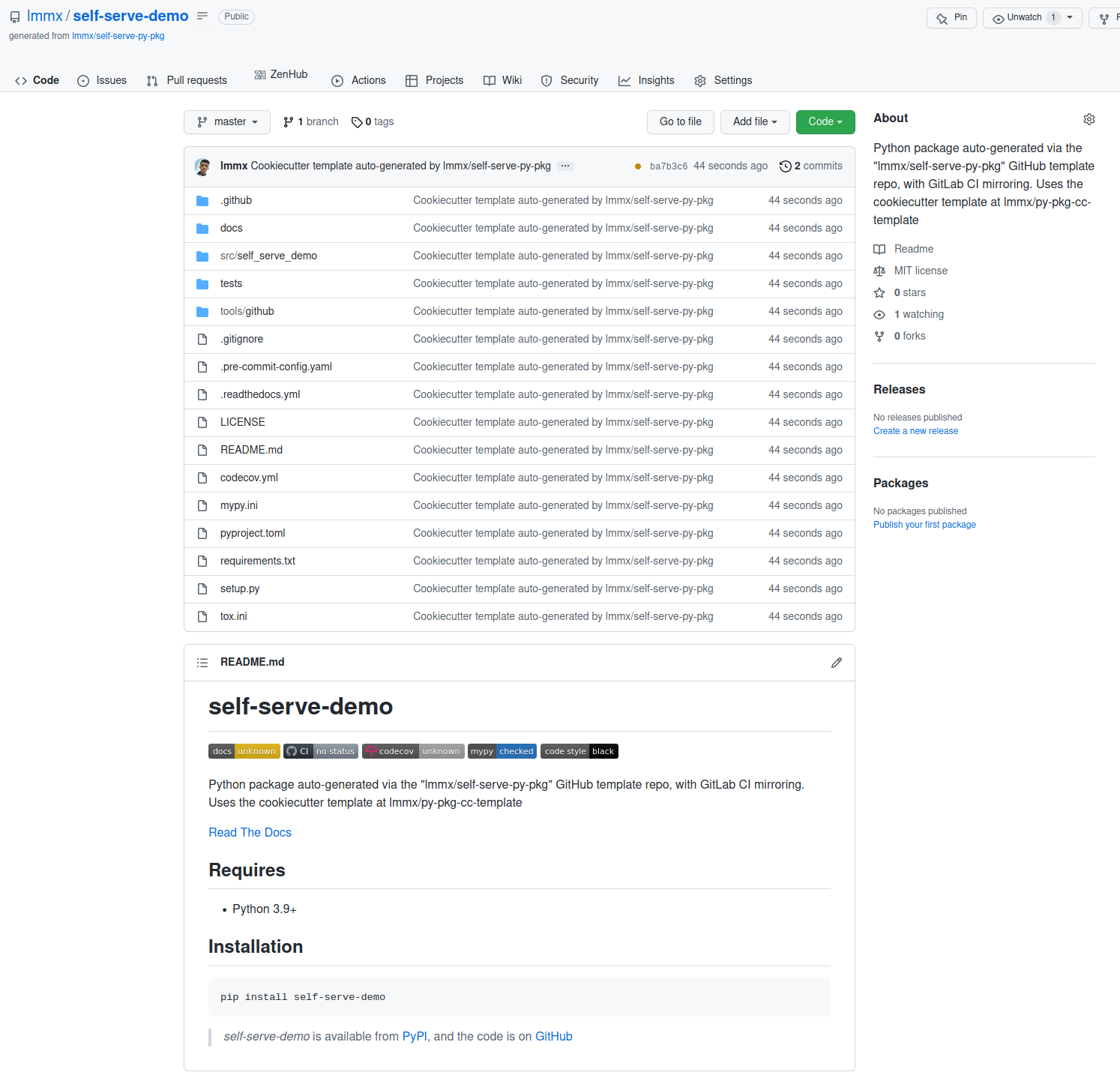
After: this is the result of passing in the name "self-serve-demo" as the package name and waiting a few seconds for the GitHub and GitLab CI workflows to run.